
III - The Technology Underlying ChatGPT
Training and Fine-Tuning ChatGPT models
After its introduction in December 2022, ChatGPT was hailed as
"The best artificial intelligence chatbot ever released to the general public" by The New York Times.
A writer for The Guardian named Samantha Lock praised its ability to produce "impressively detailed" and "human-like" writing.
After using ChatGPT to complete a student assignment, technology journalist Dan Gillmor concluded that "academia has some very significant difficulties to tackle" because the generated content was on par with what a decent student would deliver.
Among "the generative-AI eruption" that "may transform our perspective about how we work, think, and what human creativity truly is," Derek Thompson placed ChatGPT in The Atlantic's "Breakthroughs of the Year" for 2022.
According to Vox contributor Kelsey Piper, "ChatGPT is the general public's first hands-on introduction to how powerful modern AI has gotten, and as a result, many of us are [stunned]" and "clever enough to be useful despite its flaws."
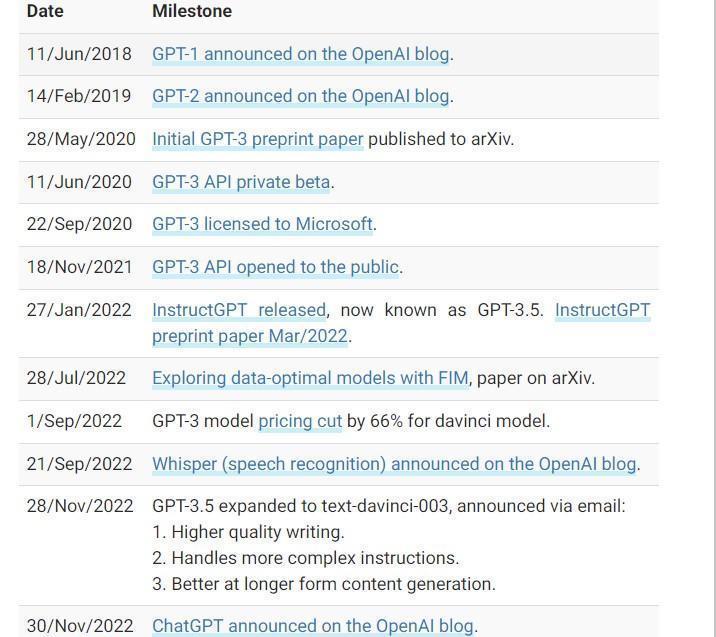
ChatGPT, short for "generative pre-training transformer," is an innovative AI technique created by OpenAI that improves the accuracy and fluency with which chatbots can understand and generate natural language. With 175 billion parameters and the ability to comprehend billions of words in a second, it is the most advanced and comprehensive language model ever built. To accomplish its goals, ChatGPT-3 pre-trains a deep neural network on a large body of text and then fine-tunes it for individual tasks like question answering and content generation. The network consists of layers, or "transformer blocks," which work together to analyze the input text and predict the desired output. ChatGPT’s ability to grasp the flow of a discussion and provide pertinent replies is one of its most impressive characteristics. This is made feasible by self-attention processes that let the network prioritize certain words and phrases in the input text based on their significance to the task.
Now we know that ChatGPT is based on the GPT model's third iteration. But just what is GPT? Let's get started with a non-technical explanation of the acronyms.
GPT's "Generative" part refers to its capacity to produce text in a human-sounding, natural language.
The model has been trained on a limited dataset, as shown by the "pre-trained." Like taking a test after reading a book (or numerous books) on the subject.
The "Transformer" alludes to the machine-learning framework that provides the muscle for GPT.
To summarize, Generative Pre-trained Transformer (GPT) is an internet-trained language model designed to produce human-language text responding to requests. As such, we have repeatedly stated that GPT was trained, but how exactly was it trained?
First, as mystical as ChatGPT may appear, it was created by human brilliance, just like every other significant software technology. OpenAI developed ChatGPT, a revolutionary AI research and development business responsible for groundbreaking AI tools like DALL-E, InstructGPT, and Codex. ChatGPT’s ability to generate coherent and consistent text from a small set of input words is another strong suit. Transformers are used because they simulate long-range dependencies in the input text and produce logical string outputs. A deep learning model known as a Transformer serves as the basis for ChatGPT's underlying technology. Researchers from Google published a study in 2017 in which they described a neural network design that they called "The Transformer." The attention mechanism, which gives the model the ability to determine how much weight to give various aspects of the input while making predictions, is the most important new feature introduced by the Transformer. This makes it possible for the model to handle sequential data such as text in a more efficient manner than was possible with earlier architectural approaches. ChatGPT is based on large language models (LLMs). LLMs are deep learning models trained on large amounts of text data to generate human-like language. These models are trained using unsupervised learning techniques and are capable of generating highly coherent and semantically meaningful text.
The Transformer-based model is trained on massive amounts of text data, typically in the order of billions of words, and capable of generating highly coherent, coherent, and semantically meaningful text. The ChatGPT model is designed to process and analyze user input in real time and generate a text response that is semantically meaningful, coherent, and relevant to the user's request or question. This is achieved by using the LLM to analyze the user's input and generate a text response that is semantically meaningful, coherent, and relevant to the user's request or question.
The ChatGPT architecture is a subtype of the Transformer framework that was developed specially to carry out natural language processing jobs. It does this by analyzing a substantial amount of text data to discover the patterns and connections between words and sentences in human language. Because of this, the model can generate material comparable to human language in terms of grammatical structure, vocabulary, and writing style. Unsupervised learning, a type of pre-training in which the model is trained on a huge amount of text input without any labels or a specific task in mind, is utilized as well. This helps the model generalize for usage in various tasks performed further down the pipeline.
The ChatGPT language model is a large-scale language model built on transformer architecture. It was trained using unsupervised learning on a large corpus of text data, enabling it to generate human-like prose. On top of GPT-3.5, ChatGPT was modified using supervised learning and reinforcement learning for optimal performance. Human trainers were utilized in each of these methods to increase the performance of the model. During the process of supervised learning, the model was exposed to dialogues in which the trainers took on the role of both the user and the AI assistant. These interactions were used to teach the model. During the reinforcement step, human trainers began by ranking the model's previous responses during another conversation. These rankings were utilized in creating reward models,' which were then fine-tuned using numerous iterations of proximal policy optimization to improve upon (PPO). The use of proximal policy optimization algorithms offers a cost-effective benefit compared to the use of trust region policy optimization algorithms; these algorithms eliminate many computationally expensive procedures while also improving performance. The training of the models took place using Microsoft's Azure supercomputing infrastructure in conjunction with Microsoft.
In addition, OpenAI is continuously collecting data from users of ChatGPT, which may be used in the future to train further and improve the accuracy of ChatGPT. ChatGPT uses a process called autoregression to produce answers. Autoregression is a method where the model generates text one token (word or punctuation mark) at a time based on the previous tokens it has generated. Users have the option to either upvote or downvote the responses they receive from ChatGPT. In addition, when users upvote or downvote a response, they are presented with a text box in which they can provide additional feedback. It does this by learning patterns and correlations between words and phrases in human language by looking over a vast corpus of text data and making connections between the words and phrases it finds.
It is important to note that ChatGPT was not originally trained to do what it does. Instead, it's an improved version of GPT-3.5, developed from GPT-3 with some tweaks. During its training phase, the GPT-3 model used a humongous quantity of information gathered from the web. Those curious about how GPT training works know that GPT-3 was trained using a hybrid of supervised learning and Reinforcement Learning via Human Feedback (RLHF). In the first, "supervised," phase, the model is taught using a massive collection of web-scraped text. In the reinforcement learning phase, it is taught to make decisions that align with what people would consider being made and correct.
Large Language Models (LLMs): A Technology Underlying ChatGPT
Large Language Models (LLMs) are a crucial technology underlying ChatGPT. LLMs are advanced artificial intelligence models that use deep learning techniques to analyze and process natural language data. These models are trained on massive amounts of data, typically in the order of billions of words, enabling them to generate highly coherent, coherent, and semantically meaningful text.
LLMs are trained using a technique known as unsupervised learning, where the model is exposed to a large corpus of text and encouraged to generate language patterns and relationships on its own. The objective is to enable the model to capture language use patterns and generate new text that resembles human-generated text. Once trained, LLMs can be used for various tasks, including text generation, classification, question answering, and conversation modeling. In the case of ChatGPT, LLMs are used to generate text responses to user input in real time. The model analyzes the user's input and generates a semantically meaningful response, coherent and relevant to the user's question or request.
LLMs have several advantages over traditional language models. Firstly, they can process and analyze vast amounts of data, which enables them to generate more coherent and semantically meaningful text than traditional models. Secondly, they can adapt and improve over time as they are trained on new data and exposed to new language patterns. Finally, LLMs can be fine-tuned for specific use cases, allowing for highly-specific language models that are capable of generating text for specific industries or domains.
In conclusion, Large Language Models (LLMs) are a critical technology that enables ChatGPT to generate text responses that are semantically meaningful, coherent, and relevant to user input. Their ability to process and analyze vast amounts of data, adapt and improve over time, and be fine-tuned for specific use cases makes them a powerful tool for enabling advanced language-based AI applications.
The following is an explanation of ChatGPT's functionality in broad strokes:
Unsupervised learning is utilized for training the model using a large corpus of text data, which typically consists of billions of words. During this phase of the training process, the model obtains the knowledge necessary to accurately represent the structures and connections that exist between the words and phrases that make up the language
After it has been trained, the model can be used for a wide variety of natural language processing activities, including the production of text, the translation of languages, the answering of questions, and many more.
When the model is given a specific task, such as generating a response to a given prompt, it uses the patterns it learned while it was being trained to generate text that is comparable to human-written text in terms of grammar, vocabulary, and style. For example, when the model is given the task of generating a response to the given prompt, it generates the response.
This is accomplished by the model digesting the input prompt, parsing it into smaller components such as individual words or phrases, and then using its internal representations of these parts to construct a response that makes sense.
When making predictions, the model uses attention to determine the relative relevance of various input components. As a result, the model can handle sequential material, such as text, more effectively than possible with earlier designs. After that, the text that was generated is what is returned as the output.
It is essential to keep in mind that ChatGPT, like any other AI model, cannot comprehend the text; rather, it merely generates text according to the patterns it has observed throughout its training process. Here is a general overview of the process ChatGPT uses to produce answers:
The model receives an input prompt, a piece of text to which the model is supposed to respond.
The model encodes the input prompt into a fixed-length vector representation called a "context vector." This context vector contains information about the meaning and structure of the input prompt.
The model then generates the first token of the output by sampling from a probability distribution over all possible tokens based on the context vector.
The model then generates the next token by sampling from a probability distribution over all possible tokens based on the context vector and the previously generated token.
This process is repeated until the model generates a stop token, indicating the end of the output, or a maximum output length is reached.
The final output is a sequence of tokens generated by the model, which is then decoded back into human-readable text.
ChatGPT uses a large amount of data and computational resources during this process, which allows it to generate text similar to human-written text in terms of grammar, vocabulary, and style.
It's important to note that while the model generates coherent and fluent text, it needs to understand its meaning. It simply generates text based on patterns and relationships learned during training.

How ChatGPT works (Source: OpenAI)
In conclusion, the underlying technology of ChatGPT is based on large language models (LLMs), specifically Transformer-based models, which are trained on vast amounts of text data to generate human-like language. These models can process and analyze user input in real time, generating a text response that is semantically meaningful, coherent, and relevant to the user's request or question. ChatGPT's functionality could shift when new developments in the field are studied. But its basic operating principles will remain unchanged until a game-changing new technology appears.
To better grasp the idea of response prediction, think of ChatGPT as a detective trying to solve a murder. The evidence is delivered to the investigator, but they still need to find out who did it or how. The investigator may not be able to "predict" with 100% certainty who committed the murder or how it was committed, but with enough evidence, they can make a strong case against the suspect(s). ChatGPT discards the original data it received from the internet and keeps the neural connections or patterns it learned. ChatGPT treats these associations or patterns as evidence when formulating a response to a question.
ChatGPT can also be compared to a very competent investigator. It cannot anticipate the specific facts of an answer, but it does an amazing job of anticipating the most likely sequence of human language text that would provide the best answer. This is how inquiries are answered. Technically speaking, ChatGPT is quite intricate. However, in its most basic form, it functions in the same way that humans do: by picking up new information and applying it when given a chance.
References:
(2023). ChatGPT for (Finance) research: The Bananarama Conjecture. Finance Research Letters, 103662.
The “Transformative Innovation” series is for your reading-listening pleasure. Order your copies today!
Regards, Genesys Digital (Amazon Author Page) https://tinyurl.com/hh7bf4m9

.jpeg)


.jpeg)
.jpeg)

.jpeg)
.jpeg)