.jpeg)
History and Development
“On November 30, 2022, San Francisco-based OpenAI, the developers of DALLE 2 and Whisper, released a new app called ChatGPT. The public could use the service at no cost at launch, with the intention of charging for it afterwards OpenAI speculated on December 4 that there were more than a million ChatGPT users”.
OpenAI initially developed the GPT (Generative Pre-trained Transformer) language model. OpenAI is both a research organization and a firm. Its primary mission is to create and advance "friendly AI" in a way that is conducive to the general welfare of humankind. They are dedicated to the research and development of cutting-edge AI technologies such as deep learning and reinforcement learning, as well as the distribution of these advanced AI technologies to a diverse audience of users through the utilization of resources such as open-source software, developer APIs, and cloud services. In addition, they research the social and economic repercussions of AI and seek to ensure that the benefits of AI are shared by as many people as is practically practicable. In addition, they are well-known for developing GPT models with significant quantities of data, one of the most popular language models. ChatGPT is a variation on this model.
The history and development of ChatGPT can be traced back to the development of the original GPT model in 2018. The GPT model was first introduced in a paper by OpenAI researchers titled "Language Models are Unsupervised Multitask Learners." The model was trained on a massive dataset of internet text and used a transformer architecture, which had previously been introduced in the paper "Attention Is All You Need" by Google researchers. This first version was trained on an enormous amount of text data, which enabled it to generate text that resembled that produced by humans. The first version of the GPT model was trained using a huge dataset of text from the internet. It could generate language that resembled that written by humans when presented with a certain challenge. It is a big language model that generates text that appears to be written by humans by employing techniques from deep learning. The transformer architecture allowed the model to process large amounts of text data effectively, and the pre-training on internet text allowed the model to learn a wide range of language patterns and structures. The GPT model was able to generate human-like text and perform well on various language understanding tasks, such as language translation and question answering. The model's ability to generate human-like text was particularly noteworthy, as it demonstrated that a machine-learned model could produce text that was difficult to distinguish from text written by a human.
Since it was initially made available to the public, OpenAI has made available many updated versions of the model. Each of these new versions contains additional data and computational resources compared to the one that came before it, making the model even more effective. Although the technology that underpins ChatGPT is regarded as cutting-edge for its day, it is not the most recent nor the most cutting-edge AI model currently accessible. Artificial intelligence is always undergoing research and development, leading to the creation of brand-new models and methodologies.
Following the success of the original GPT model, OpenAI released many variants of the model, including GPT-2 and GPT-3. GPT-2, released in 2019, was a larger version of the original model, with 1.5 billion parameters. The model was trained on a dataset of internet text that was even larger than the dataset used to train the original GPT. GPT-2 demonstrated an even greater ability to generate human-like text and perform a wide range of language tasks. ChatGPT-2 is a variant of the GPT-2 (Generative Pre-trained Transformer 2) model developed by OpenAI. It is specifically designed for conversational language generation tasks such as chatbots, virtual assistants, and conversational interfaces. Like GPT-1, ChatGPT-2 is pre-trained on a large dataset of internet text, allowing it to learn a wide range of language patterns and structures. However, ChatGPT-2 is fine-tuned on a dataset of conversational data, such as dialogue transcripts, to improve its ability to generate appropriate and coherent responses to user input. This fine-tuning allows the model to generate more natural and human-like responses to user input, allowing for more natural and human-like conversations.
ChatGPT-2 can generate human-like text and perform a wide range of language tasks with minimal task-specific training. This makes it an attractive choice for developers and researchers looking to build conversational AI systems. ChatGPT-2 is a variant of GPT-2 which is fine-tuned for conversational language generation tasks. It is trained on a conversational dataset, allowing it to generate more natural and human-like responses to user input, and it can understand the context of the conversation and continue it seamlessly.
In 2020, OpenAI released ChatGPT-3, which was even larger than GPT-2, with 175 billion parameters. ChatGPT-3 is a variation of GPT-3, specifically trained to generate conversational responses. The model is fine-tuned on conversational data, such as dialogue transcripts, to improve its ability to generate appropriate and coherent responses to user input. The pre-training data for ChatGPT-3 is a combination of conversational data and internet text, which is fine-tuned to generate more natural and human-like responses to user input, allowing for more natural and human-like conversations. ChatGPT-3 is a powerful model used in various applications, such as chatbots, virtual assistants, and conversational interfaces. The model's ability to generate human-like text and perform a wide range of language tasks with minimal task-specific training makes it an attractive choice for developers and researchers looking to build conversational AI systems. GPT-3 received much attention for its ability to generate human-like text and perform a wide range of language tasks with minimal task-specific training. The model was trained on a dataset of internet text, several orders of magnitude larger than the dataset used to train GPT-2. GPT-3's ability to perform a wide range of language tasks with minimal task-specific training was particularly noteworthy, as it demonstrated that a machine-learned model could be capable of learning a wide range of language understanding tasks from a single large dataset of internet text.
In addition to GPT-2 and GPT-3, OpenAI released several other variants of the GPT model, including GPT-3 Small, GPT-3 Medium, GPT-3 Large, and GPT-3 XL. These variants have slightly different architectures and are fine-tuned on specific datasets to perform tasks such as language translation and question answering.
Each ChatGPT model is trained with a particular emphasis on conversational language. It has been fine-tuned on a dataset of conversational text to improve its capacity to generate realistic and cohesive responses throughout a conversation. In addition, ChatGPT's performance in various areas, including question and answer, summarization, and others, has been fine-tuned to improve its ability to carry out particular tasks. It is one of the most advanced conversational AI models currently available, and it is utilized in various applications, including chatbots, virtual assistants, and conversational interfaces. ChatGPT is considered to be one of the most advanced conversational AI models. After the GPT-3.5, ChatGPT was modified using supervised learning and reinforcement learning to achieve optimal performance. Human trainers were utilized in these methods to increase the model's performance.
During the process of supervised learning, the model was exposed to dialogues in which the trainers took on the role of both the user and the AI assistant. These interactions were used to teach the model. During the reinforcement step, human trainers began by ranking the model's previous responses during another conversation. These rankings were utilized in creating “reward models,” which were then fine-tuned using numerous iterations of proximal policy optimization to improve upon (PPO). The use of proximal policy optimization algorithms offers a cost-effective benefit compared to the use of trust region policy optimization algorithms; these algorithms eliminate many computationally expensive procedures while also improving performance. The training of the models took place using Microsoft's Azure supercomputing infrastructure in conjunction with Microsoft.
In addition, OpenAI is continuously collecting data from users of ChatGPT, which may be used in the future to train further and improve the accuracy of ChatGPT. Users can either upvote or downvote the responses they receive from ChatGPT. When users upvote or downvote a response, they are presented with a text box in which they can provide additional feedback.
On November 30, 2022, the most recent and updated prototype of ChatGPT was released, and it soon gained notice for its thorough responses and articulate answers across a wide range of subject areas. After the launch of ChatGPT, OpenAI's market capitalization increased to $29 billion.
Although ChatGPT, like all other AI systems, cannot feel emotions or form goals, it cannot be considered "friendly" in the word's conventional meaning. On the other hand, it was conceived and developed to serve and be advantageous to people. It can generate writing similar to that produced by humans, and it may be used for a wide variety of purposes, including the processing of natural languages, the translation of languages, the answering of questions, and more. However, it is essential to understand that ChatGPT is a machine-learning model. This model gives answers based on patterns it has seen while being trained, and it is only as good as the data it was trained on.
Google announced its response to OpenAI’s ChatGPT: “Bard.” It is currently undergoing rigorous testing by trusted users before being made available for public use in H1 2023. Bard is based on a lightweight version of Google's LamDA (Language Model for Dialogue Applications) that requires lower computational power.
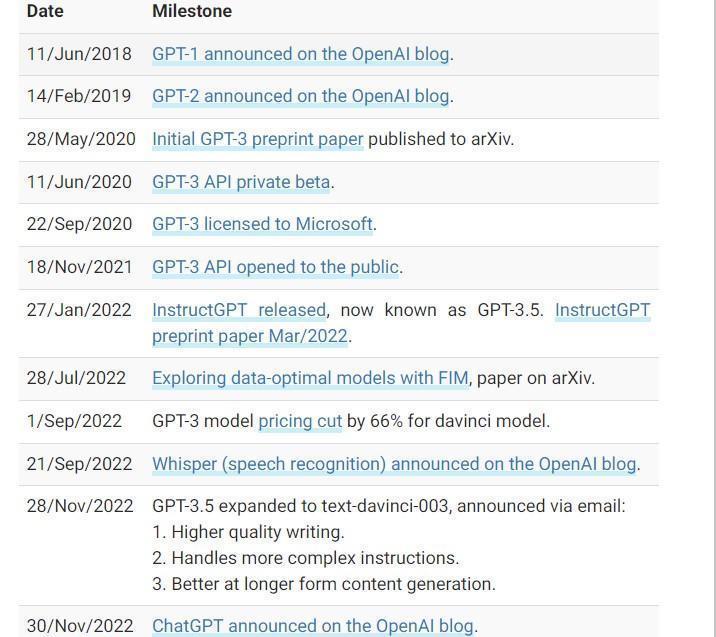
Table. Timeline from GPT-1 to ChatGPT. (Source: GPT-3.5 + ChatGPT: An illustrated overview (2023) Dr. Alan D. Thompson – Life Architect.
In conclusion, ChatGPT can be traced back to OpenAI's 2018 invention of the GPT (Generative Pre-training Transformer) AI language model. To do this, GPT was trained on a massive corpus of human-generated text to understand how sentences are put together and anticipate the next word in a given sequence. Machine translation, language synthesis, and even musical composition are just a few fields that have benefited from this technology's rapid adoption.
OpenAI's team, inspired by GPT's success, set out to design a chatbot that could carry on convincing human-to-human interactions. Because of this, ChatGPT was created and made available to the public in 2020. After years of development, one of the most sophisticated chatbots today is based on ChatGPT.
Resources:
What is ChatGPT? A brief history and look to a bright future (2023) Electrode.
The “Transformative Innovation” book series is available on Amazon for your reading-listening pleasure. Order your copies today!
Regards, Genesys Digital (Amazon Author Page) https://tinyurl.com/hh7bf4m9


.jpeg)
.jpeg)
No comments:
Post a Comment