Natural Language Processing (NLP) is a field of Artificial Intelligence that deals with the interaction between computers and human languages. It uses computational techniques to process, analyze, and generate human language. The goal of NLP is to enable computers to understand, interpret, and generate human language in a way that is as natural as possible. The field of computer science known as natural language processing (NLP) focuses on teaching machines to mimic human language comprehension to translate written text and spoken language. Combining statistical, machine learning, and deep learning models with computational linguistics (rule-based modeling of human language) is what natural language processing (NLP) is all about. As a whole, these innovations equip computers with the ability to 'understand' the full meaning of human language, including the speaker's or writer's intent and sentiment, in the form of text or audio data.
Machines using natural language processing can now translate between languages, follow verbal instructions, and quickly summarize vast amounts of text, sometimes in real-time. In the form of voice-operated GPS systems, digital assistants, speech-to-text dictation software, customer service chatbots, and other consumer conveniences, NLP is something you've already engaged with. However, natural language processing (NLP) is now playing an increasingly important role in enterprise solutions that aim to improve the efficiency of businesses, boost employee productivity, and simplify crucial business processes.
Natural Language Generation (NLG) is a subfield of NLP that deals with the automatic generation of natural language text or speech from structured data. The goal of NLG is to produce text or speech that is similar to human-written text or speech. This can be used for tasks such as text summarization, machine translation, and automatic writing is a field of AI that deals with the interaction between computers and human languages, and it involves using computational techniques to process, analyze and generate human language. NLG is a subfield of NLP that deals with the automatic generation of natural language text or speech from structured data.
It is extremely challenging to develop software that correctly identifies the intended meaning of text or voice data due to the ambiguities inherent in human language. Programmers must educate natural language-driven systems to identify and interpret effectively from the outset the peculiarities of human languages, such as homonyms, homophones, sarcasm, idioms, metaphors, grammatical and usage exceptions, and differences in sentence structure.
Various NLP tasks dissect the human text and voice data into smaller pieces that are easier for the computer to process. The following are examples of some of these responsibilities:
Speech recognition, often known as a speech-to-text conversion, is the process of accurately transcribing audio recordings into text. Any program that listens for spoken instructions or inquiries and responds verbally must have speech recognition. How people speak—fast, jumbled up, with shifting emphasis and intonation, in diverse accents, and often with faulty grammar—makes speech identification particularly difficult.
The technique of assigning a label to a word or passage of text based on how it is typically used is known as part of speech tagging or grammatical tagging. "I can make a paper plane" is an example of the verb form, while "what make of automobile do you own" is the noun form.
Word sense disambiguation is the process of using semantic analysis to identify the most appropriate meaning of a word that can have many meanings. One use of word sense disambiguation is to tell the difference between the two meanings of the verb "make," as in "make the grade" (achieve) and "make a bet" (put a wager) (place).
The NEM technique recognizes key concepts embedded in the text. NEM recognizes "Kentucky" as a state in the United States and "Fred" as a male-given name.
Determining whether or not two words refer to the same thing is known as coreference resolution. Common examples include replacing pronouns with their correct names (such as "she" for "Mary") and spotting instances of metaphor and idiom (such as "bear" for "big hairy person").
Sentiment analysis aims to identify and understand the underlying attitudes, emotions, sarcasm, bewilderment, and mistrust expressed in written communication.
Putting structured information into human language is the goal of natural language generation, commonly contrasted with speech recognition or speech-to-text.
To use ChatGPT, you can input a prompt or question, and the model will generate a response based on its training. You can use ChatGPT for various tasks, such as language translation, writing, and conversation. You can interact with the model through a user interface or by making API calls. You can also fine-tune the model for specific tasks by training it on a dataset that is relevant to the task. ChatGPT can be applied in natural language processing and generation tasks in a few ways:
Fine-tuning: ChatGPT is a pre-trained language model that uses a technique called fine-tuning to adapt to specific natural language tasks. Fine-tuning involves training the model on a small amount of task-specific data while keeping the pre-trained weights fixed. This allows the model to learn task-specific representations from the new data while leveraging the general knowledge it already acquired during pre-training. Fine-tuning can be used for a wide range of natural language tasks, including language translation, question answering, and text generation. One of the most common ways to apply ChatGPT in natural language processing is by fine-tuning the pre-trained model on a specific task or dataset. For example, the task is to build a chatbot. In that case, the model can be fine-tuned on a dataset of conversational data, such as dialogue transcripts, to improve its ability to generate appropriate and coherent responses to user input.
Text generation: ChatGPT can generate human-like text, such as writing essays, articles, and stories. It can also generate automated responses to customer inquiries, chatbot conversations, and more. ChatGPT generates text using autoregression, which involves predicting the next word in a sequence of text based on the preceding words. A neural network architecture powers a “transformer” designed to handle sequential data. The model is trained on a large text dataset, allowing it to learn patterns and relationships between words, phrases, and sentences. During the training process, the model learns to recognize patterns in the input data, such as the relationship between certain words and phrases, which enables it to generate new text similar to the input data. When generating text, the model starts with a prompt, a set of input text that provides context for the text being generated. The model then uses its trained parameters to predict the next word in the sequence based on the input prompt. The process is repeated, and each time the model predicts a new word, the prompt is updated to include the new word, and so on.
The model can be fine-tuned to generate text for specific applications by training it on a smaller, relevant dataset. The fine-tuning process allows the model to adapt to the specific characteristics of the dataset and improve its performance on the task. In summary, ChatGPT generates text using a neural network architecture called a transformer and autoregressive process. It starts with a prompt and predicts the next word in the sequence by using the context of the input prompt. The model can be fine-tuned to generate text for specific applications by training it on a smaller, relevant dataset.
Language understanding: ChatGPT can extract meaning and understand the context of user input. This allows the model to generate more accurate and relevant responses. ChatGPT uses a type of neural network called a transformer to understand and generate natural language. The transformer architecture allows the model to attend to different parts of the input and output sequences, which allows it to focus selectively on the most relevant information when processing or generating text. The model is pre-trained on a large corpus of text data, which enables it to learn general knowledge about the structure and meaning of natural language. During this pre-training, the model learns to encode the input text into a representation that captures its meaning and to decode this representation into a coherent output text. During fine-tuning, the model is further trained on a task-specific dataset, which allows it to learn task-specific representations and generate text that is relevant to the specific task. For example, when fine-tuned on a Q&A dataset, the model can use the context of a question to generate an answer that is relevant and informative. In summary, ChatGPT uses a transformer-based neural network to learn general and task-specific representations of natural language, enabling it to understand and generate text in various natural language processing tasks.
Language generation: One of the most obvious applications of ChatGPT is in language generation. The model can be used to generate text that is similar to human-written text. This can be used for tasks such as text summarization, machine translation, and automatic writing. ChatGPT uses language generation to produce coherent and natural-sounding text in various natural language processing tasks. The model is trained to predict the next word in a sequence of words, given the previous words, which enables it to generate coherent and fluent text.
During pre-training, the model learns to generate text similar to the text in the training corpus, enabling it to learn about the structure and style of natural language. During fine-tuning, the model is further trained on a task-specific dataset, which allows it to learn task-specific representations and generate text that is relevant to the specific task.
For example, when fine-tuned on a question-answering task, the model can use the context of a question to generate a coherent and informative answer. When fine-tuned on a language translation task, the model can use the source text to generate a coherent and natural-sounding translation in the target language. When fine-tuned on a text completion task, the model can use the given context to generate readable and natural-sounding text to complete the given prompt.
In summary, ChatGPT uses language generation to produce coherent and natural-sounding text in various natural language processing tasks. The model is trained to predict the next word in a sequence of words, which enables it to generate fluent and coherent text relevant to the specific task it's fine-tuned on.
Question-Answering: ChatGPT can be fine-tuned for question-answering tasks. It can be trained on a dataset of question-answer pairs to generate answers to questions it has not seen before. ChatGPT uses question answering (QA) to understand and generate text in a natural language processing task. QA is a task in which the model receives a question and must generate an answer based on the given context. During pre-training, the model learns to encode the input text into a representation that captures its meaning and to decode this representation into a coherent output text. This enables the model to learn about the structure and meaning of natural language and to understand the context of a given question.
During fine-tuning, the model is further trained on a QA dataset, which allows it to learn task-specific representations and generate text that is relevant to the specific task. The fine-tuning process enables the model to learn to extract and reason over the information in the context to generate a coherent and informative answer. For example, when given a question like "What is the capital of France?", the model can extract the information from the context that "France" is a country and that capital is the city that serves as the administrative center of a country. It then generates an answer, "Paris," which is France's correct capital. In summary, ChatGPT uses question-answering to understand and generate text in a natural language processing task. The model is fine-tuned on a QA dataset to learn task-specific representations and generate coherent and informative answers based on the context of the question.
Multi-Turn Dialogue: ChatGPT can be fine-tuned to handle multi-turn dialogue, where the model can keep track of the context and the conversation flow. This allows the model to generate more natural and human-like responses. ChatGPT uses multi-turn dialogue for natural language processing and generation. Multi-turn dialogue is the process of conducting a conversation between two or more participants, where each participant takes turns speaking and responding.
During pre-training, the model learns to encode the input text into a representation that captures its meaning and to decode this representation into a coherent output text. This enables the model to learn about the structure and meaning of natural language and to understand the context of a given conversation. During fine-tuning, the model is further trained on a dialogue dataset, which allows it to learn task-specific representations and generate text that is relevant to the specific task. The fine-tuning process enables the model to learn to maintain the context of the conversation, understand the conversation flow, and generate coherent and natural-sounding responses.
For example, when fine-tuned on a dialogue dataset, the model can use the context of previous turns in the conversation to generate coherent and natural-sounding responses. It can also understand the conversation's intent and generate responses relevant to the conversion goal. ChatGPT uses multi-turn dialogue for natural language processing and generation. The model is fine-tuned on a dialogue dataset to learn task-specific representations and generate coherent and natural-sounding responses based on the context of the conversation and the conversation flow.
Language Translation: ChatGPT can translate text from one language to another, such as English to Spanish. ChatGPT can be used for language translation by fine-tuning the model on a parallel corpus, a dataset containing sentences in two languages (e.g., English and Spanish) that have been translated from one language to the other. The fine-tuning process can be done by training the model on a smaller dataset relevant to the translation task. The model learns to recognize patterns and relationships between words, phrases, and sentences in the two languages, enabling it to generate translations similar to the input data.
Once fine-tuned, the model can translate new sentences by providing a sentence in one language and asking it to generate a translation in another. The model uses its trained parameters to generate a new sentence in the target language that is similar to the input sentence. One way to do this is to use the Encoder-Decoder architecture, where the encoder encodes the input sentence into a fixed-length representation, and the decoder generates the translation from this representation. It's worth noting that machine translation is a challenging task, and the quality of the translation depends on the quality of the dataset used during the fine-tuning process. Also, it's important to note that the model can be fine-tuned for a specific pair of languages, for example, English-Spanish, but it would only be able to translate between other language pairs with additional fine-tuning. ChatGPT can be used for language translation by fine-tuning the model on a parallel corpus dataset. Once fine-tuned, the model can translate new sentences by providing a sentence in one language and asking it to generate a translation in another. The quality of the translation depends on the quality of the dataset used during the fine-tuning process, and it's important to note that the model can be fine-tuned for a specific pair of languages.
Text summarization: ChatGPT can automatically summarize text by extracting the most important information from a document or article. ChatGPT can be used for text summarization by fine-tuning the model on a dataset of text that has been manually summarized. The fine-tuning process can be done by training the model on a smaller dataset relevant to the summarization task. The model learns to recognize patterns and relationships between words, phrases, and sentences in the text, which enables it to generate summaries similar to the input data. Once fine-tuned, the model can be used to summarize new text by providing it with a longer piece of text and asking it to generate a shorter summary containing the most important information. One way to do this is to use the Extractive summarization method, which involves selecting the most important sentences or phrases from the text and concatenating them to form the summary. Extractive summarization methods can be based on keyword frequency, sentence importance, or other criteria.
Another approach is the Abstractive summarization method, which involves generating new phrases and sentences that convey the most important information from the input text. This approach is more challenging than extractive summarization but provides more human-like summaries. It's worth noting that text summarization is a challenging task, and the quality of the summary depends on the quality of the dataset used during the fine-tuning process. Also, the model can be fine-tuned for a specific type of text, such as news articles, but it would only be able to summarize other types of text with additional fine-tuning. In summary, ChatGPT can be used for text summarization by fine-tuning the model on a manually summarized dataset. Once fine-tuned, the model can be used to summarize new text by providing it with a longer piece of text and asking it to generate a shorter summary containing the most important information. Text summarization is a challenging task, and the summary quality depends on the quality of the dataset used during the fine-tuning process. The model can be fine-tuned for a specific type of text, such as news articles.
Sentiment analysis: ChatGPT can determine text sentiment, such as whether a sentence expresses a positive or negative emotion. ChatGPT can be used for sentiment analysis by fine-tuning the model on a dataset of text that has been manually labeled with sentiment scores. The fine-tuning process can be done by training the model on a smaller dataset relevant to the sentiment analysis task. The model learns to recognize patterns and relationships between words, phrases, and sentences in the text, which enables it to predict the sentiment of new text. Once fine-tuned, the model can be used to predict the sentiment of a new text by providing it with a piece of text and asking it to generate a sentiment score or label (e.g., positive, negative, or neutral).
There are different ways to represent the sentiment of text, but one of the most common is to use a binary classification approach, where the model is trained to predict whether a piece of text is positive or negative. Another approach is a multi-class classification approach, where the model is trained to predict text sentiment from a set of predefined labels (e.g., positive, negative, neutral). It's worth noting that sentiment analysis is a challenging task, and the model's accuracy depends on the quality of the dataset used during the fine-tuning process. Also, the model can be fine-tuned for a specific type of text, such as tweets, but it would only be able to analyze the sentiment of other types of text with additional fine-tuning. ChatGPT can be used for sentiment analysis by fine-tuning the model on a dataset of text that has been manually labeled with sentiment scores. Once fine-tuned, the model can be used to predict the sentiment of a new text by providing it with a piece of text and asking it to generate a sentiment score or label. Sentiment analysis is a challenging task, and the model's accuracy depends on the quality of the dataset used during the fine-tuning process. The model can be fine-tuned for a specific type of text, such as tweets.
Text classification: ChatGPT can classify text into different categories, such as spam or non-spam emails or positive or negative reviews. ChatGPT can be used for text classification by fine-tuning the model on a dataset of text manually labeled with predefined categories. The fine-tuning process can be done by training the model on a smaller dataset relevant to the text classification task. The model learns to recognize patterns and relationships between words, phrases, and sentences in the text, enabling it to predict the new text category. Once fine-tuned, the model can be used to predict the category of a new text by providing it with a piece of text and asking it to generate a label or classification (e.g., spam or not spam, positive or negative)
There are different types of text classification, such as:
Binary classification: Binary classification is a text classification with the goal of predicting one of two possible outcomes or classes. The two classes are typically labeled as "positive" and "negative." In NLP, binary classification can be used for various applications, including sentiment analysis, spam detection, and topic categorization. For example, a binary classifier can be trained in sentiment analysis to predict whether a given text represents positive or negative sentiment. In spam detection, the binary classifier is trained to predict whether an email is spam.
ChatGPT, it can be used for binary classification by fine-tuning the pre-trained language model on a large corpus of labeled text data for a specific task. During the fine-tuning process, the model learns to associate certain words and phrases with either the positive or negative class. Once the model is trained, it can then be used to make predictions on new, unseen text data. Binary classification is a fundamental task in NLP and is a building block for more complex tasks, such as multi-class classification or sequence labeling.
Multi-class classification: Multi-class classification is a text classification problem in which the goal is to assign a text document or sequence of words to one of multiple classes or categories. It is commonly used in natural language processing applications to categorize text data into predefined categories, such as sentiment analysis (positive, negative, neutral), news articles (sports, politics, entertainment), or product reviews (electronics, books, clothing). ChatGPT, a language model developed by OpenAI, can be used for multi-class classification in NLP. For example, it can be trained on a large dataset of text documents to recognize the sentiment of a given text by assigning it to the positive, negative, or neutral class. During the training process, the model learns the patterns and features in the text data indicative of each class.
Once the model is trained, it can then be used to predict the sentiment of new text data by analyzing the features of the text and assigning it to the class with the highest predicted probability. This enables ChatGPT to perform sentiment analysis on new text data in real time, making it a useful tool for businesses and organizations to monitor and analyze customer sentiment. Overall, multi-class classification is a powerful tool for text classification in NLP, and ChatGPT is a highly capable model for performing this type of task.
Multi-label classification: Multi-label classification is a type of text classification where each document or text can belong to multiple classes or categories simultaneously rather than just one class, as in traditional binary or multiclass text classification. For example, in a movie classification task, a movie can belong to multiple genres, such as action, adventure, and sci-fi, at the same time. Multi-label classification can be applied to various NLP tasks such as sentiment analysis, topic classification, and intent classification. ChatGPT can perform multi-label classification tasks by fine-tuning its pre-trained transformer-based architecture on a labeled text dataset. The fine-tuned model can then predict the probabilities of a given text belonging to multiple classes. Applications of multi-label classification with ChatGPT in NLP include:
Sentiment analysis: where a document can be classified as having multiple sentiments, such as positive, negative, and neutral, at the same time.
Topic classification: a document can be classified into topics such as politics, sports, and entertainment.
Intent classification: where a text can belong to multiple intents, such as providing information, making a recommendation, and answering a question.
Multi-label classification with ChatGPT can be useful in several NLP and text generation tasks as it allows for a more nuanced understanding of the text and can help better capture the multiple facets of a text.
It's worth noting that text classification is a challenging task, and the model's accuracy depends on the quality of the dataset used during the fine-tuning process. Also, the model can be fine-tuned for a specific type of text, such as news articles, but it would only be able to classify other text types with additional fine-tuning.
In summary, ChatGPT can be used for text classification by fine-tuning the model on a dataset of text that has been manually labeled with predefined categories. Once fine-tuned, the model can be used to predict the category of a new text by providing it with a piece of text and asking it to generate a label or classification. Text classification is a challenging task, and the model's accuracy depends on the quality of the dataset used during the fine-tuning process. The model can be fine-tuned for a specific type of text, such as news articles.
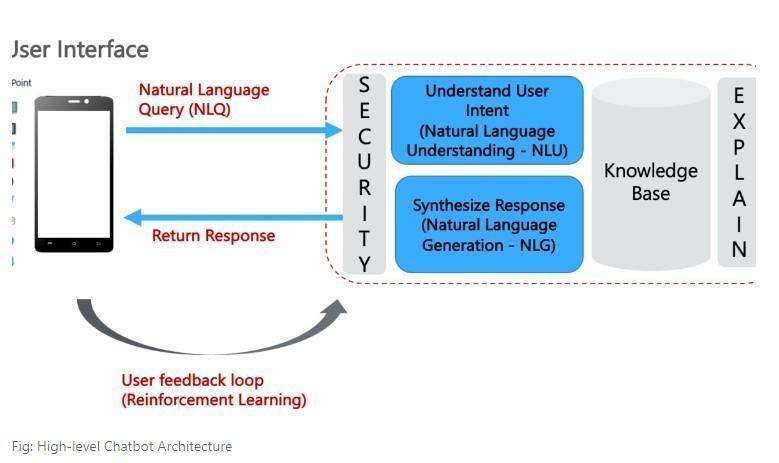
High-level Chatbot Architecture
Source: Biswas, D. CHATGPT, and its implications for enterprise AI, LinkedIn.
In summary, ChatGPT can be applied in natural language processing and generation tasks by fine-tuning the pre-trained model on specific tasks or datasets, using it for language understanding, language generation, question answering, and handling multi-turn dialogues. This means that this sentence says that ChatGPT is a powerful tool that can be used for various tasks related to natural language processing and generation. These tasks include but are not limited to language understanding, language generation, question answering, and handling multi-turn dialogues.
"By fine-tuning the pre-trained model on specific tasks or datasets" - To perform these tasks, the model needs to be fine-tuned on specific datasets or tasks. Fine-tuning is adapting the pre-trained model to a new task or dataset by continuing the training process on this new dataset. This allows the model to learn task-specific representations and generate text that is relevant to the specific task.
"Using it for language understanding" - One of the tasks ChatGPT can use is language understanding. This refers to the ability of the model to understand the meaning of the input text. During fine-tuning, the model learns to encode the input text into a representation that captures its meaning, which enables it to understand the context and intent of the text.
"Language generation" - Another task ChatGPT can be used for is language generation. This refers to the model's ability to produce coherent and natural-sounding text. During fine-tuning, the model learns to predict the next word in a sequence of words, enabling it to generate fluent and coherent text relevant to the specific task it's fine-tuned on.
"Question answering" - One of the NLP tasks ChatGPT can use is question answering. This refers to the ability of the model to understand and generate text in a natural language processing task. The model is fine-tuned on a QA dataset to learn task-specific representations and generate coherent and informative answers based on the context of the question.
"Handling multi-turn dialogues" - Another task ChatGPT can be used for is handling multi-turn dialogues. This refers to the ability of the model to maintain the context of the conversation, understand the conversation flow, and generate coherent and natural-sounding responses. The model is fine-tuned on a dialogue dataset to learn task-specific representations and generate coherent and natural-sounding responses based on the context of the conversation and the conversation flow.
ChatGPT is a versatile and powerful tool with many uses in natural language processing (NLP) and text generation. It can automate tasks related to understanding and generating human language, making it useful for various industries and groups, including businesses, researchers, and developers. ChatGPT has a wide range of applications within NLP and text generation, making it a valuable tool for many users and use cases.
Resources:
The workings of ChatGPT, the latest natural language processing tool. Varahasimhan;
Franciscu, Shehan. (2023). ChatGPT: A Natural Language Generation Model for Chatbots.
Chen; How ChatGPT is revolutionizing natural language processing.
The “Transformative Innovation” series is for your listening-reading pleasure. Order your copies today!
Regards, Genesys Digital (Amazon Author Page) https://tinyurl.com/hh7bf4m9


.jpeg)
.jpeg)
No comments:
Post a Comment